
New Feature: Automated Client & Case Management

New Feature: Discovery Response Due Dates (Automated)

Can a Machine Practice Law? It Depends.

Machines can’t practice law.
The statement is apparently obvious, but it’s implications are not:
In 2015, the court in Lola v. Skadden (linked here) affirmed the parties’ determination that “an individual who . . . undertakes tasks that could otherwise be performed entirely by a machine cannot be said to engage in the practice of law.”
The key here is the understanding of what constitutes a task “that could otherwise be performed entirely by a machine.”
In 2015 this meant document review.
But that definition will only expand as new tech continues to automate an increasing portion of legal work (see e.g., Clearbrief, Draft Builders, Briefpoint, etc.).
In 2022, companies are already working on facilitating end-to-end litigation document automation. Once they do, what’s left for the practice of law?
Certainly things like depositions, court appearances, client interviews, generating creative arguments, framing the facts in the light most favorable for their client, and anything else that requires the “black box of intuition.”
Will this change what you can bill a client for?
No – ABA Rule 1.5 permits billing for tasks necessary to conduct your representation and does not require that the activity constitute “the practice of law” (see e.g., billing for travel).
The major implication I predict is the proliferation of things like Arizona’s Alternative Business Structures – business entities that provide legal services and include nonlawyers with economic interests or decision-making authority.
If successful, this structure might look a lot like the relationship between doctors’ officers and their PAs: lawyers work over an office of paralegals conducting routine legal work and providing low-level legal advice.
And I think the potential pitfalls are similar too: an inexperienced paralegal’s bad advice may fall to the lawyer to fix, as is sometimes the case with doctors and PAs.
What does this ruling say in light of Upsolve?
By way of brief background, the Upsolve case involved Upsolve’s (an MGLD company) generation and provision of Chapter 7 filing documents to non-attorney petitioners. (See Briefpoint’s full article on the Upsolve case here). There, the court found that the company had engaged in the unauthorized practice of law because, among other things, it provided a finite number of legal options through which the petitioner-user could use Upsolve to draft their petition.
While non-binding, Upsolve’s underlying facts are meaningfully different than those in Lola v. Skadden because Lola v. Skadden involved the automation of documents for attorneys – not pro se litigants.
To recall the doctor analogy: while a pharmaceutical company may provide doctors with a medical “short-cut” for healing a patient, they do not themselves prescribe the medication to the patient – or even offer a finite amount of potential treatments for the same. Similarly, while an MGLD may provide attorneys a “short-cut” for resolving their clients’ disputes, they should not themselves do the same for unlicensed consumers – at least not directly.
Indirectly, an MGLD company may get around “unauthorized practice” by hiring licensed attorneys to stand-in as middlemen between the MGLD and the end-user (such is loosely the case with the Marble Law – an incredible company who’s similarly incredible vision would see the provision of legal services sold at transparent, flat rates).
Accordingly – and for now – it seems that Upsolve and Lola’s reconciliation stems from the end-user of the product: MGLD for attorneys = permissible, MGLD for non-attorneys = unauthorized.
Of course, life is never so cut-and-dry, this article does not constitute legal advice, and, if you are an MGLD company seeking guidance on what constitutes the practice of law, seek counsel.
Machine Generated Legal Document (MGLD) Platform Found to Engage in Unauthorized Practice of Law

For the first time, an AI-backed legal tech platform was found to have engaged in the unauthorized practice of law.
The case centered around the machine generated legal document (MGLD) platform Upsolve.
Upsolve automates “the information intake process and [preparation of] bankruptcy forms that [are] then reviewed by an attorney.”
In other words, Upsolves takes data and uses it to generate a document that would otherwise be generated by an attorney.
The lawsuit involved a pro-per petitioner that used Upsolve to help draft a voluntary Chapter 7.
Given that the document appeared to be written by an attorney, the court was suspicious of how this petitioner came to draft it “without counsel.” Because Upsolve was identified as the platform that assisted the petitioner in drafting, the court entered an Order to Show Cause to Upsolve.
In its defense, Upsolve argued that it had systems to filter out users “whose situations might require specialized advice or the exercise of legal judgment,” and that the software was “user-driven.”
The court didn’t buy it, asserting that “the moment the software limits the options presented to the user based upon the user’s specific characteristics – thus affecting the user’s discretion and decision-making – the software provides the user with legal advice.”
It makes intuitive sense: if a non-lawyer seeking legal advice asks an attorney “what their options are,” the attorney’s response (a limited set of legal options) would understandably constitute legal advice.
Presumably, Upsolve could have avoided liability if its platform was sold to bankruptcy attorneys who then acted as middlemen between Upsolve’s insights and their advice to petitioners.
This would not be so different from the relationship between pharmaceutical companies and doctors: pharmaceutical companies effectively provide doctors with a range of treatment options for a specified ailment and the doctors relay those limited options to a patient.
Taking the analogy one step further, MGLD platforms like Upsolve might still be able to market to non-lawyer individuals with the caveat that they “talk to their attorney about Upsolve” (mirroring drug commercials ending with “talk to your doctor about _____”).
It certainly would cut against Upsolve’s mission to provide affordable tools for individuals to proceed in simple bankruptcy proceedings, but an avenue nonetheless.
This is likely the first of many cases involving what MGLD processes constitute the practice of law and it’s incredibly exciting to be around at the start of what will be a fascinating tug-of-war between technical advancement and what it means to practice law.
PS – It’s worth noting that Upsolve’s click-to-accept disclosure stating “I understand that the Upsolve software acts entirely at my own direction and that Upsolve does not have the authority or ability to provide legal services” was found to be insufficient by the court. Some things you can’t just click-away. But, if you are looking to maximize your click-to-accept agreements’ enforceability, use Ironclad.
Briefpoint Now Processes DISC-002, DISC-003, and DISC-005

Briefpoint announced today that it launched new processing capabilities for Form Interrogatory DISC-002 (employment), DISC-003 (unlawful detainer), and DISC-005 (construction).
All users have the ability to process these documents without any additional cost to their subscription.
To upload a form interrogatory, simply drag and drop it on your Briefpoint dashboard, at which point they will process automatically.
Additionally, Briefpoint now allows users to customize their preliminary statements for each type of discovery request.
Briefpoint’s new processing capabilities reflect Team Briefpoint’s dedication to automating the entirety of the discovery process – from response to compel.
For more information on Briefpoint and its plans to facilitate end-to-end litigation automation, email Support@briefpoint.ai with the subject line “Briefpoint Roadmap.”
READ MOREHow to (Theoretically) Replace Your Judge with AI



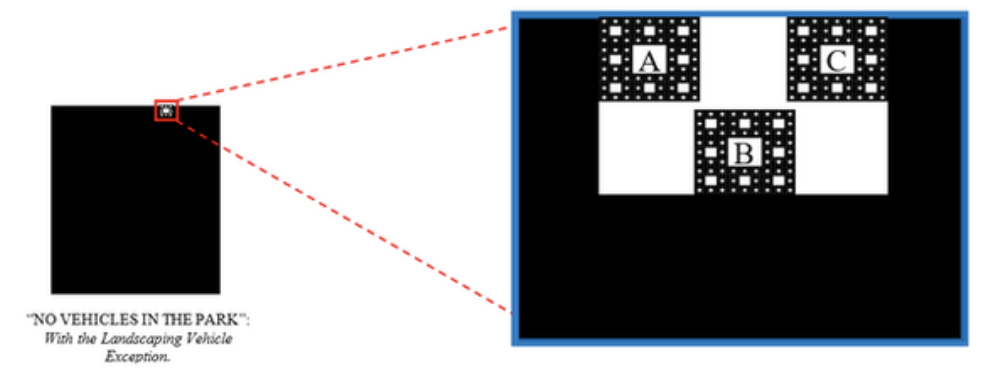
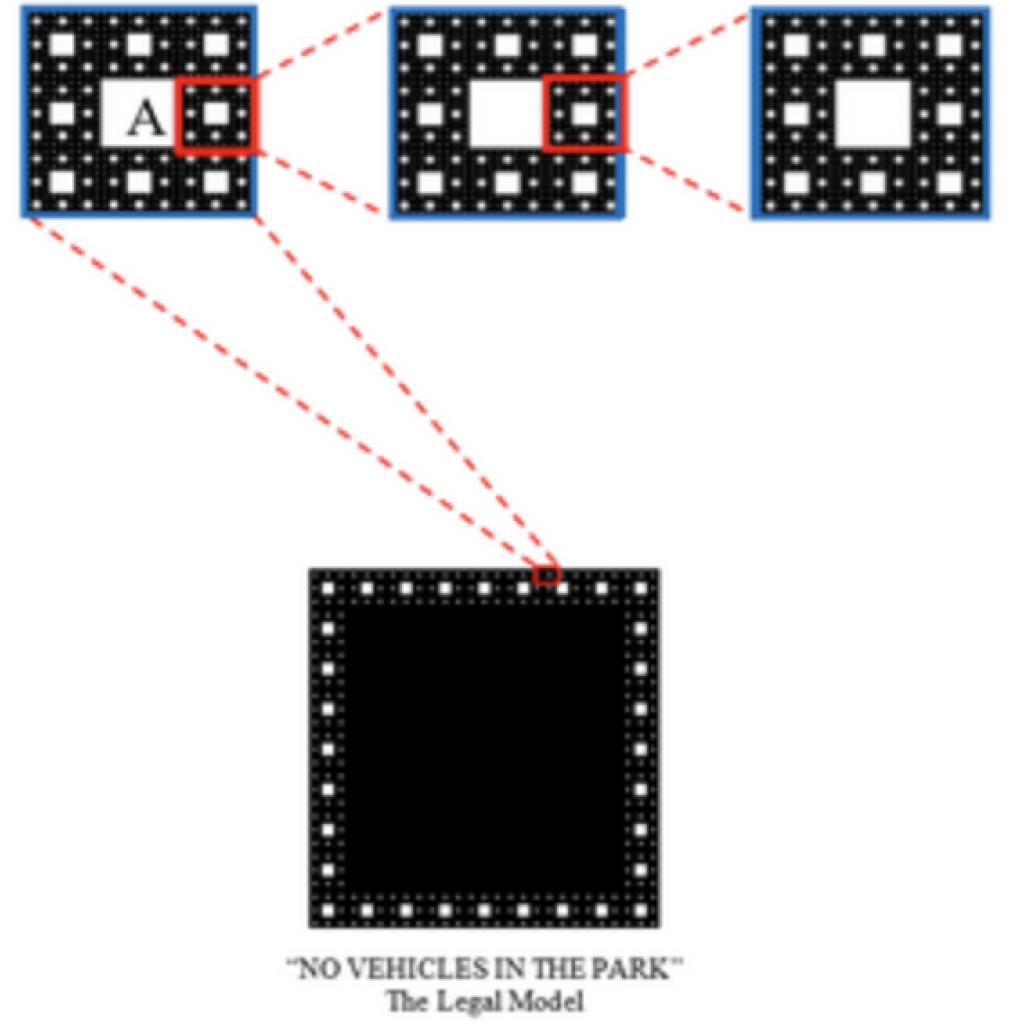
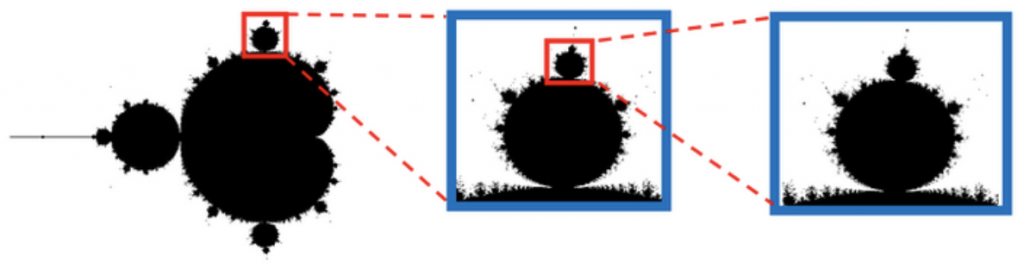



When Machine Learning Takes the Stand
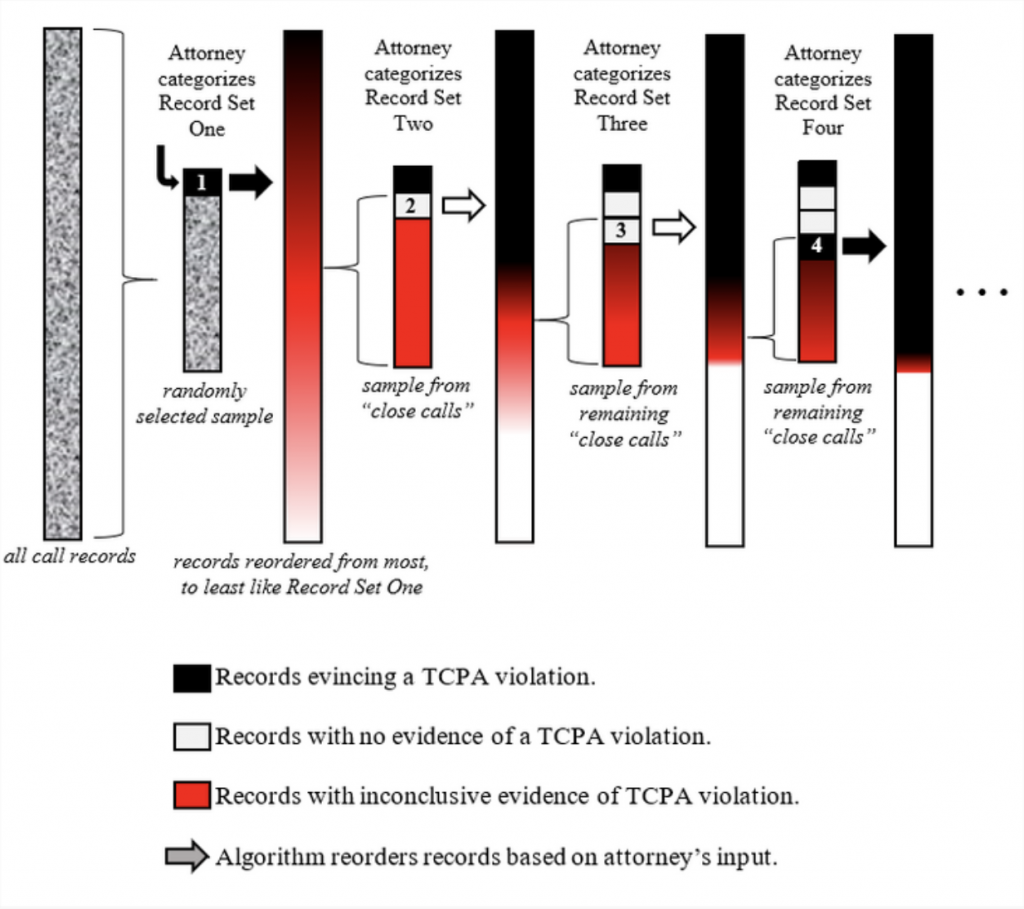
5 Legal Tech Solutions That You Can Actually Use